
In het verleden heb ik enkele berichten geschreven over het verwerken/verzamelen van gegevens van Profcoach om deze informatie in een verbeterd overzicht te verwerken. De beperking hierbij was dat de verwerking altijd met Excel gedaan moest worden. Voor seizoen 2012/2013 heb ik een nieuwe oplossing gezocht, welke succesvol is ingezet gedurende het hele seizoen.
Hoe Profcoach gegevens verzamelen?
Om online de gegevens te verwerken zijn er een aantal oplossingen beschikbaar, zo schreef ik in 2012 over een oplossing met Yahoo Pipes!. Helaas is deze oplossing te beperkt en heb ik gezocht naar andere oplossingen welke uit de datajournalistiek komen. Hiervoor zijn diverse offline en online oplossingen te vinden, denk hierbij aan:
- Software pakketten; volledige pakketten welke te installeren zijn op je computer om de data te verzamelen en te verwerken;
- Browser plugins; kleine software modules die als addon aan de web browser worden toegevoegd;
- Online tooling; Web based systemen die middels scripting taal informatie verwerken en opslaan.
Tijdens vergelijking van deze systemen ben ik terecht gekomen bij ScraperWiki welke het meest aan mijn wensen en eisen voldeed. Dit mede vanwege de onafhankelijkheid van een fysieke computer om de verwerking te doen. Een Open Source systeem die ondersteuning biedt om data periodiek te verzamelen en mogelijkheden biedt om deze data (middels een API interface) te presenteren.
Welke informatie ophalen en verwerken?

Eenmaal voor ScraperWiki te hebben gekozen, is er op basis van enkele voorbeelden een verwerkingsscript geschreven met Python. De keuze voor Python aangezien dit een relatief eenvoudige scriptingtaal is en vrij krachtig in de verwerking van HTML. Alvorens te starten met de verwerking van de data uit Profcoach is er eerst een vereenvoudigd datamodel gemaakt in navolging van de stappen die bij datajournalistiek aan bod komen (te weten: data –> filter/verrijk –> visualiseer –> verslag/artikel).
Welke Python code is er geschreven?
De volgende Python code is uiteindelijk gebruikt om de data te verzamelen en te filteren of verrijken zodat dit aan de behoefte voldeed om een juiste geautomatiseerde analyse uit te voeren van de door de diverse coaches opgestelde teams.
[code language=”Python” collapse=”true”] # –[ ABOUT Profcoachscraper ]—————————————————# This scraper has been build to retrieve data from the profcoach.nl website.
# The website provides an online soccer management game, but does not have enough
# statistical information.
# Therefore this scraper has been build.
# Constant values
# —————
# Values that will be used within the scraper (team set-up/systems and the team_id’s that need to be scraped).
aSyst = [‘4-4-3’, ‘4-4-2’, ‘3-4-3’, ‘3-5-2’]
dataSource = [‘3e6b62fe-b970-4c13-99d6-089933c03d53’, ‘1ddb8b2d-d8c3-4c74-a1a2-51abaa61d944’, ‘6a9ce8ed-b559-44f5-9d63-610d72a3c941’]
# Import libraries
# —————-
# List all the libraries that are neccesary in order to process the data.
import scraperwiki
import mechanize
import cookielib
import lxml.html
from lxml import etree
# Definitions
# ———–
# Generic ‘functions’ that will be called during the execution of the scraper.
#Retrieve the teamname form the root object
def get_teamname(root):
h1 = root.cssselect(‘h1’)[0].text_content().strip()
return h1
#Get max x players within a list of players
def getmax(players, playertype, number=4):
scores = [x[‘player_pntscor’] for x in players if x[‘player_type’]==playertype]
scores.sort()
return sum(scores[-number:])
#Get the indexvalue of the position in the list.
def index_max(values):
return max(xrange(len(values)),key=values.__getitem__)
# –[ START Processing ]——————————————————–
# As the data of profcoach.nl is only available after logging into the database
# we are forced to use the Mechanize library to get out the HTML so we can
# process the data.
# Browser
# ——-
# Make use of Mechanize as we need to be logged on to see the data
br = mechanize.Browser()
# Cookie Jar
cj = cookielib.LWPCookieJar()
br.set_cookiejar(cj)
# Browser options
br.set_handle_equiv(True)
br.set_handle_gzip(True)
br.set_handle_redirect(True)
br.set_handle_referer(True)
br.set_handle_robots(False)
# Follows refresh 0 but not hangs on refresh > 0
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
# User-Agent (this is cheating, ok?)
br.addheaders = [(‘User-agent’, ‘Mozilla/5.0 (Windows NT 6.1; rv:15.0) Gecko/20120716 Firefox/15.0a2’)]
# Open profcoach.nl website to able to logon to eredivisie.nl
r = br.open(‘http://profcoach.nl/Team/6016e43e-4ba6-48de-9bad-904cf977c51d’)
# Find the correct link to logon ‘Registreren / Login’
br.find_link(text=’Registreren / Login’)
# Actually clicking the link
req = br.click_link(text=’Registreren / Login’)
br.open(req)
# Select the first (index zero) form
br.select_form(nr=0)
# User credentials – DUMMY User has been created for this!!!
br.form[‘email’] = ‘dummy.profcoachuser@gmail.com’
br.form[‘password’] = ‘dummyPCScraper’
# Login
br.submit()
# –[ MAIN Processing section ]————————————————-
# This section will loop through the teams that have been defined in the
# ‘dataSource’ variable. For all those teams the data will be retrieved and put
# into the tables belonging to this scraper.
for source in dataSource:
# Open profcoach.nl website
r = br.open(‘http://profcoach.nl/Team/’+source)
html = r.read()
#print html # – Debugging statement
# Get General details
CaptainID = html[html.find("updateCaptain(‘")+15:html.find("’", html.find("updateCaptain(‘")+15)]
RoundInfo = html[html.find("Opstelling van ")+15:html.find("</h3>", html.find("Opstelling van ")+16)]
# Read out the data
tree = lxml.html.fromstring(html)
#Read out the Teamscore
scores = tree.cssselect(‘.box’)
RoundScore = (int(scores[0].cssselect(‘span’)[0].text_content().strip()) if scores[0].cssselect(‘span’)[0].text_content().strip().isdigit() else 0)
RoundPosition = scores[1].cssselect(‘span’)[0].text_content().strip()
RoundTotalScore = int(scores[2].cssselect(‘span’)[0].text_content().strip().replace(".", ""))
#Read details of the players in the soccer team
players = tree.cssselect(‘.player’)
for player in players:
data = {
‘player_id’ : player.get(‘personid’),
‘player_name’ : player.cssselect(‘.name’)[0].get(’title’),
‘player_points’ : int(player.cssselect(‘.team’)[0].text_content().strip()),
‘player_pntscor’ : ((int(player.cssselect(‘.team’)[0].text_content().strip())/2) if player.get(‘personid’) == CaptainID else int(player.cssselect(‘.team’)[0].text_content().strip())),
‘player_position’ : (‘Bankspeler’ if player.get(‘slot’) is None else ‘Basisspeler’),
‘player_type’ : (‘Aanvaller’ if player.get(‘class’) == ‘player pos4’ else (‘Middenvelder’ if player.get(‘class’) == ‘player pos3’ else (‘Verdediger’ if player.get(‘class’) == ‘player pos2’ else ‘Keeper’))),
‘player_captain’ : (‘Ja’ if player.get(‘personid’) == CaptainID else ‘Nee’),
‘player_team’ : get_teamname(tree),
‘player_teamid’ : source,
‘player_round’ : RoundInfo
}
#Store the retrieve data in this loop/iteration to the database
scraperwiki.sqlite.save(unique_keys=[‘player_team’, ‘player_round’, ‘player_id’], data=data, table_name="pcteamplayers")
#Query above data to get extra details for the team information
rawbench = scraperwiki.sqlite.select("sum(player_pntscor) as bnchscore from pcteamplayers where player_teamid = ‘" + source + "’ and player_round=’" + RoundInfo + "’ and player_position=’Bankspeler’" )
rawplayers = scraperwiki.sqlite.select("* from pcteamplayers where player_teamid = ‘" + source + "’ and player_round=’" + RoundInfo + "’" )
rawbestplayer = scraperwiki.sqlite.select("max(player_pntscor) as best from pcteamplayers where player_teamid = ?",source)
#Make calculation for the best team and system used
i443 = (((getmax(rawplayers, ‘Keeper’, 1)+getmax(rawplayers, ‘Verdediger’, 4)+getmax(rawplayers, ‘Middenvelder’, 3)+getmax(rawplayers, ‘Aanvaller’, 3))-rawbestplayer[0][‘best’])+(2*rawbestplayer[0][‘best’]))
i442 = (((getmax(rawplayers, ‘Keeper’, 1)+getmax(rawplayers, ‘Verdediger’, 4)+getmax(rawplayers, ‘Middenvelder’, 4)+getmax(rawplayers, ‘Aanvaller’, 2))-rawbestplayer[0][‘best’])+(2*rawbestplayer[0][‘best’]))
i343 = (((getmax(rawplayers, ‘Keeper’, 1)+getmax(rawplayers, ‘Verdediger’, 3)+getmax(rawplayers, ‘Middenvelder’, 4)+getmax(rawplayers, ‘Aanvaller’, 3))-rawbestplayer[0][‘best’])+(2*rawbestplayer[0][‘best’]))
i352 = (((getmax(rawplayers, ‘Keeper’, 1)+getmax(rawplayers, ‘Verdediger’, 3)+getmax(rawplayers, ‘Middenvelder’, 5)+getmax(rawplayers, ‘Aanvaller’, 2))-rawbestplayer[0][‘best’])+(2*rawbestplayer[0][‘best’]))
#Calculate the best team and get the corresponding system from the list
sMaxScore = max((i443), (i442), (i343), (i352))
sBstSyst = aSyst[index_max([i443, i442, i343, i352])]
# Now single datastore for the team information
scraperwiki.sqlite.save(unique_keys=["team_name", "team_round"], data={"team_id": source, "team_name":get_teamname(tree), "team_round":RoundInfo, "team_roundscore":RoundScore, "team_totalscore": RoundTotalScore, "team_roundposition":RoundPosition, "team_benchscore": rawbench[0][‘bnchscore’] ,"team_maxscore":sMaxScore, "team_bestsystem":sBstSyst}, table_name = "pcteams")
print "Succesfully scraped the details for manager: ", get_teamname(tree) [/code]
Let bij het gebruik van bovenstaande code wel op de volgende onderdelen:
- dataSource – Dit is een lijst met alle team_id’s van de Profcoach coaches in een specifieke subleague. Dit is is te achterhalen na het openen/bekijken van een team van een collega coach. In de URL vind je dit team_id terug;
- DummyUser – Om de informatie te verwerken kan je gebruik maken van je eigen Profcoach gebruikersnaam wanneer de code is afgeschermd. Wanneer de code leesbaar is raad ik je aan om gebruik te maken van een dummy gebruiker.
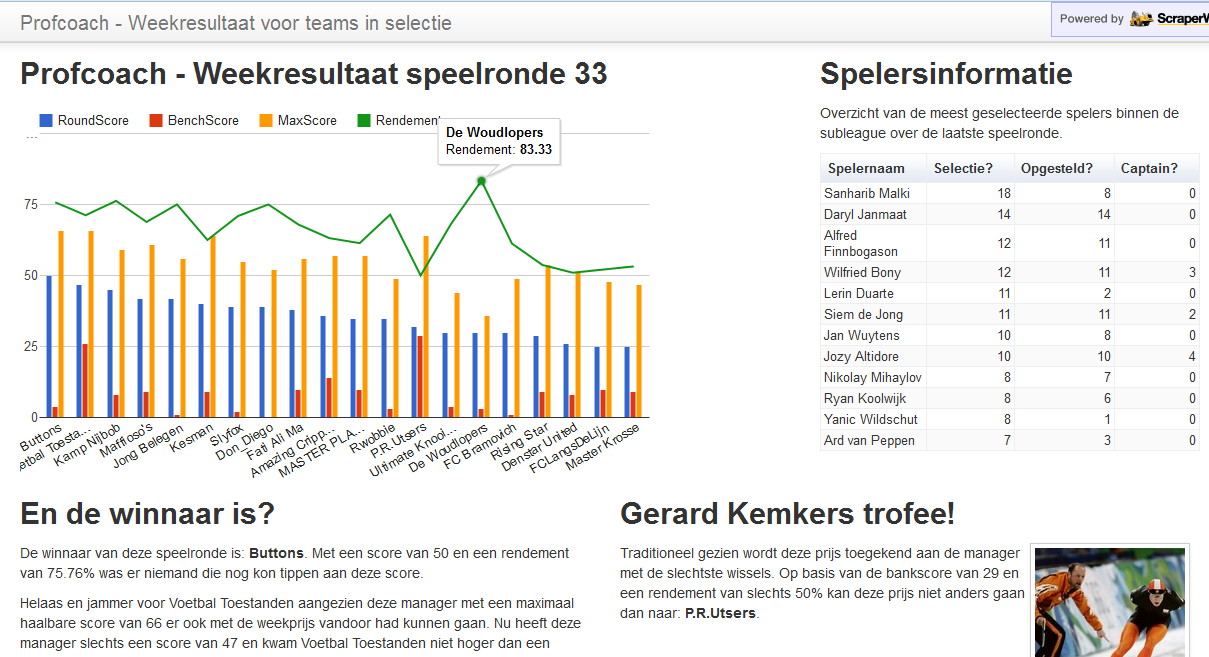
Hoe verzamelde gegevens presenteren?
Voor de subleague waarin mijn team actief was gedurende het seizoen 2012/2013 is de volgende visualisatie gemaakt met behulp van ScraperWiki views. Aangezien niet alle data tijdens de verzameling aan de wensen kon voldoen is er ook logica aan de visualisatie toegevoegd. Om deze visualisatie te maken kan er met behulp van een API data opgevraagd worden bij de eerder beschreven Scraper. Hieronder een voorbeeld van de gebruikte code.
[code language=”JavaScript” collapse=”True”]var apiurl = "https://api.scraperwiki.com/api/1.0/datastore/sqlite";var srcname = "profcoachscraper_1";
var sqlselect = "select team_name, team_roundscore, team_benchscore, team_maxscore, team_round, team_totalscore from pcteams where team_round in (select distinct team_round from pcteams order by CAST(replace(team_round, ‘speelronde ‘, ”) AS SIGNED) desc limit 1) order by team_roundscore desc, team_benchscore desc";
var sqlselectplayers = "select player_name, count(*) as in_teams, sum(player_captain = ‘Ja’) as iscaptain, sum(player_position = ‘Basisspeler’) as opgesteld from pcteamplayers where player_round in (select distinct team_round from pcteams order by CAST(replace(team_round, ‘speelronde ‘, ”) AS SIGNED) desc limit 1) group by player_name order by in_teams desc limit 12";
$.ajax({url:apiurl, data:{name:srcname, query:sqlselect, format:"jsonlist"}, dataType:"jsonp", success:ProcessTeamInfo, error: ProcessError });
$.ajax({url:apiurl, data:{name:srcname, query:sqlselectplayers, format:"jsonlist"}, dataType:"jsonp", success:ProcessPlayerInfo, error: ProcessError }); [/code]
Bovenstaande code haalt via de Scraperwiki API met behulp van JSON de benodigde informatie op. Verder verwijs ik je graag naar de broncode van de gemaakte view.
[box type=”alert” size=”large”]Let op: bovenstaande voorbeelden zijn gebasseerd op de Scraperwiki Classic. Momenteel vind er een transitie plaats naar een nieuwe Scraperwiki omgeving.[/box]Het staat een ieder vrij deze informatie te gebruiken en een eigen scraper te schrijven. Wanneer er suggesties of verbeteringen zijn hou ik mij aanbevolen. Idealiter zou het fantastisch wanneer Profcoach deze informatie zelf gaat toevoegen of wanneer zij de data beschikbaar stellen middels een API.
Pingback:Profcoach statistieken 2013 - beste spelers per linie - Ruben Woudsma